[Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 1
https://developer-ankiwoong.tistory.com/843
[Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 1
- Crawling 주제 Top 1000 : https://www.imdb.com/search/title/?groups=top_1000 IMDb "Top 1000" (Sorted by Popularity Ascending) - IMDb IMDb's advanced search allows you to run extremely powerful quer..
developer-ankiwoong.tistory.com
[Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 2
https://developer-ankiwoong.tistory.com/844
[Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 2
[Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 1 https://developer-ankiwoong.tistory.com/manage/newpost/843 TISTORY 나를 표현하는 블로그를 만들어보세요. www.tistory.com - import 모듈 import pa..
developer-ankiwoong.tistory.com
- 1페이지가 아닌 전체 페이지를 크롤링 하기 위한 작업을 생각한다.
50개의 데이터가 아닌 1000개의 데이터를 가져와야된다.
- Site 주소 확인(규칙 확인 작업)

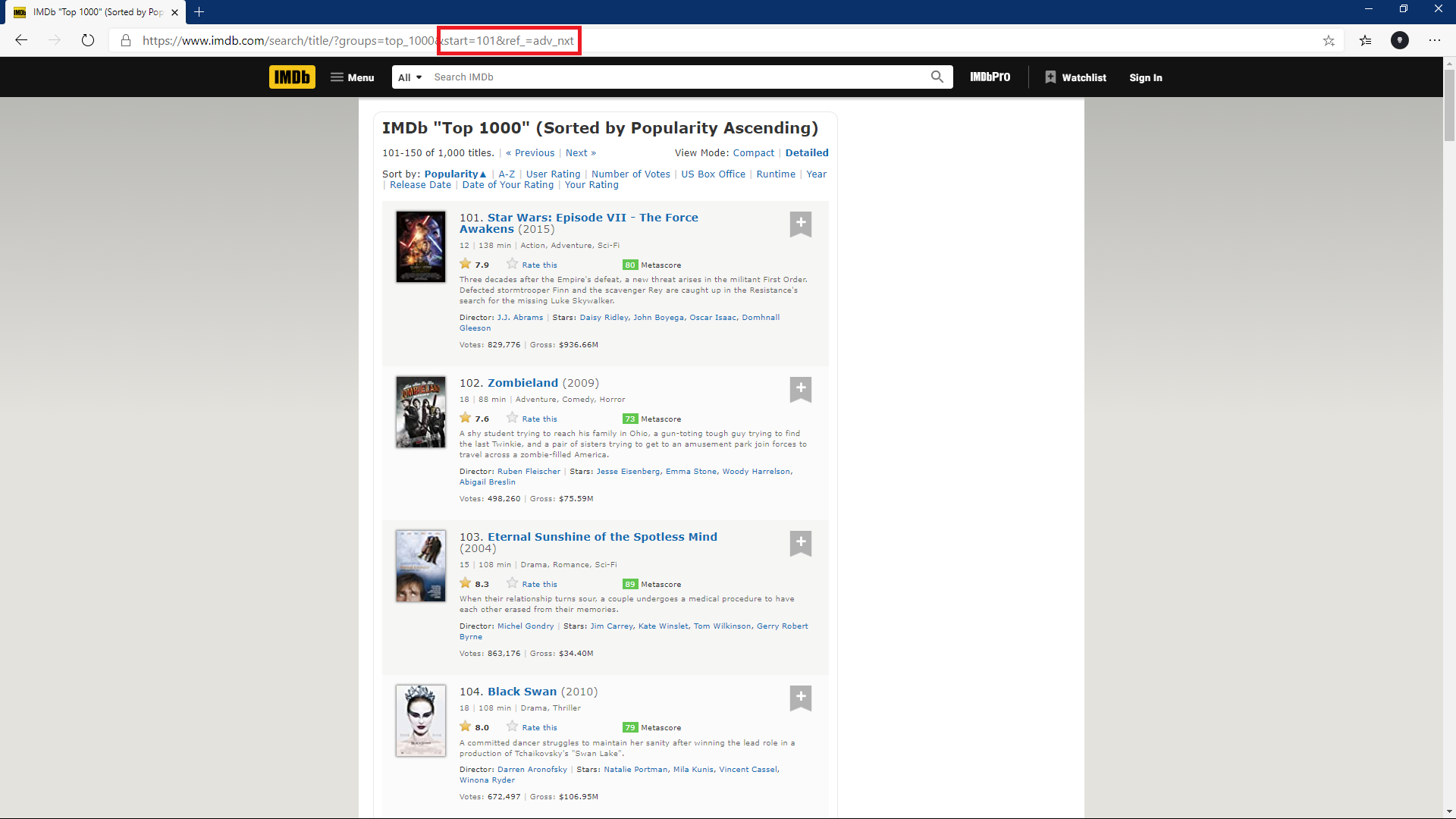
- 페이지 간격을 위한 생성
pages = np.arange(1, 1001, 50)> Result
[ 1 51 101 151 201 251 301 351 401 451 501 551 601 651 701 751 801 851 901 951]
- 사이트 주소 조합
for page in pages:
page = requests.get("https://www.imdb.com/search/title/?groups=top_1000&start=" +
str(page) + "&ref_=adv_nxt", headers=headers)
- html 파싱
soup = BeautifulSoup(page.text, 'html.parser')
- 생성
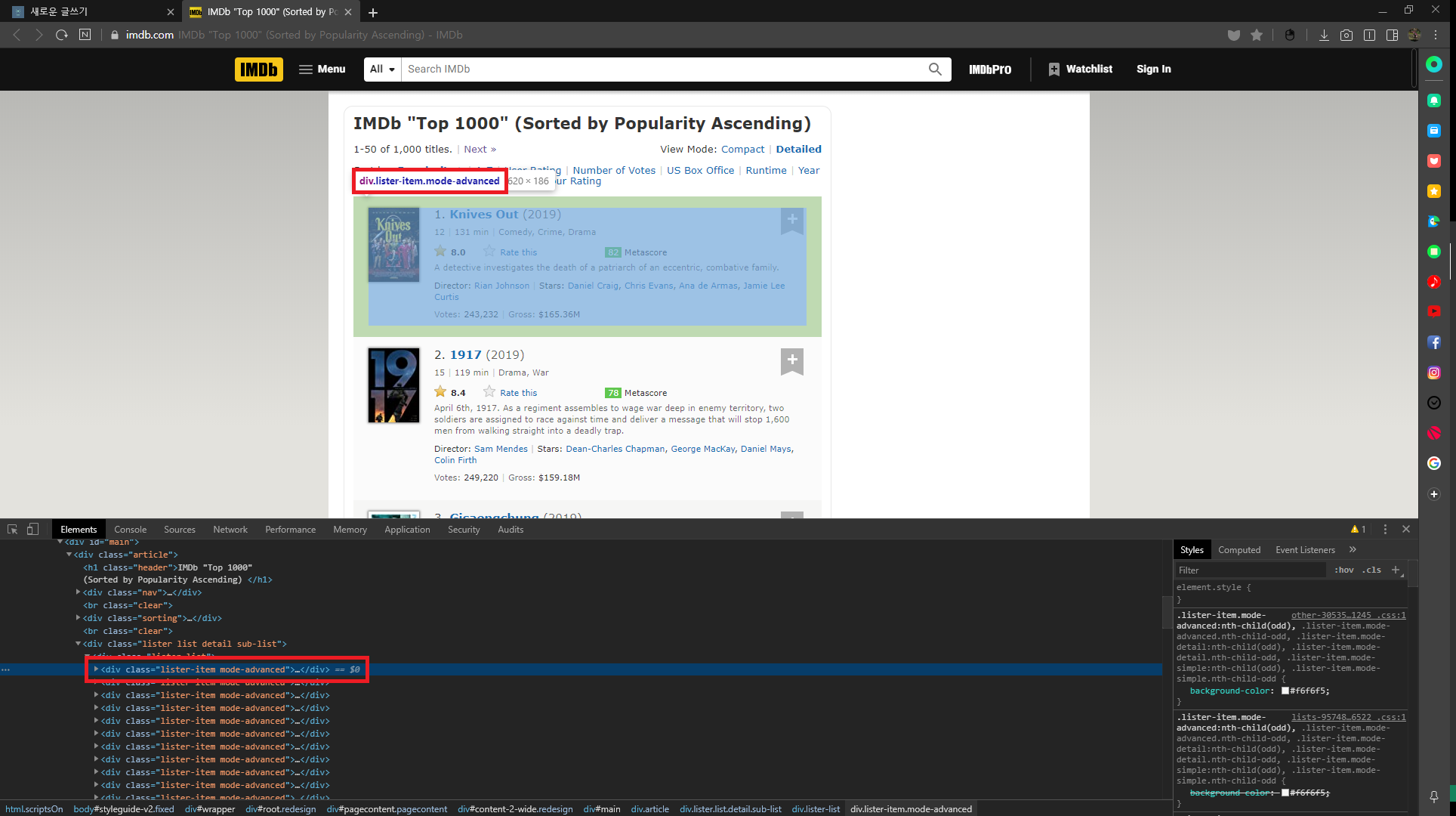
movie_div = soup.find_all('div', class_='lister-item mode-advanced')
- 크롤링 속도 제어(2 ~ 10초 사이 랜덤으로 대기 시간 지정 / 도의적인 행동)
sleep(randint(2, 10))
- Crawling Code
import requests
from requests import get
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
from fake_useragent import UserAgent
from time import sleep
from random import randint
# usaragnt 생성 및 header 정보 생성
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}
# 데이터 추출 리스트 생성
titles = []
years = []
time = []
imdb_ratings = []
metascores = []
votes = []
us_gross = []
# 페이지 생성
# 시작 끝 간격
pages = np.arange(1, 1001, 50)
for page in pages:
# 페이지 파라미터 조합
page = requests.get("https://www.imdb.com/search/title/?groups=top_1000&start=" +
str(page) + "&ref_=adv_nxt", headers=headers)
# HTML 구문 확인
soup = BeautifulSoup(page.text, 'html.parser')
movie_div = soup.find_all('div', class_='lister-item mode-advanced')
# 크롤링 속도 제어
# 2 ~ 10초 대기 시간 지정
sleep(randint(2, 10))
for container in movie_div:
# 영화 제목 추출
name = container.h3.a.text
titles.append(name)
# 개봉 년도 추출
year = container.h3.find('span', class_='lister-item-year').text
years.append(year)
# 상영 시간 추출
runtime = container.p.find('span', class_='runtime') if container.p.find(
'span', class_='runtime') else ''
time.append(runtime)
# 평점 추출
imdb = float(container.strong.text)
imdb_ratings.append(imdb)
# 메타스코어 추출
m_score = container.find('span', class_='metascore').text if container.find(
'span', class_='metascore') else ''
metascores.append(m_score)
# 투표 / 총 매출 추출을 위한 데이터
nv = container.find_all('span', attrs={'name': 'nv'})
# 투표 점수 추출
vote = nv[0].text
votes.append(vote)
# 총 매출 추출
grosses = nv[1].text if len(nv) > 1 else ''
us_gross.append(grosses)
- DataFrame 생성
movies = pd.DataFrame({
'movie': titles,
'year': years,
'imdb': imdb_ratings,
'metascore': metascores,
'votes': votes,
'us_grossMillions': us_gross,
'timeMin': time
})
- 각각 Data 전처리 과정
# 데이터 전처리 과정 - , 삭제 > 정수
movies['votes'] = movies['votes'].str.replace(',', '').astype(int)
# 데이터 전처리 과정 - ( ) 삭제 > 정수
movies['year'] = movies['year'].str.extract('(\d+)').astype(int)
# 데이터 전처리 과정 - 문자 > 특수문자 제거 > 정수
movies['timeMin'] = movies['timeMin'].astype(str)
movies['timeMin'] = movies['timeMin'].str.extract('(\d+)').astype(int)
# 데이터 전처리 과정 - 특수문자 제거
movies['metascore'] = movies['metascore'].str.extract('(\d+)')
movies['metascore'] = pd.to_numeric(movies['metascore'], errors='coerce')
# 데이터 전처리 과정 - $ M 제거
movies['us_grossMillions'] = movies['us_grossMillions'].map(
lambda x: x.lstrip('$').rstrip('M'))
movies['us_grossMillions'] = pd.to_numeric(
movies['us_grossMillions'], errors='coerce')
- 전처리 과정 후 DataFrame 확인
print(movies.head())
print(movies.tail())> Result
movie year imdb metascore votes us_grossMillions timeMin
0 Knives Out 2019 8.0 82.0 243856 165.36 131
1 1917 2019 8.4 78.0 249669 159.18 119
2 Gisaengchung 2019 8.6 96.0 333353 53.37 132
3 Uncut Gems 2019 7.6 90.0 134681 NaN 135
4 Jojo Rabbit 2019 8.0 58.0 175326 0.35 108
...
movie year imdb metascore votes us_grossMillions timeMin
995 Vizontele 2001 8.0 NaN 30651 NaN 110
996 Nefes: Vatan Sagolsun 2009 8.0 NaN 30536 NaN 128
997 Boy A 2007 7.6 75.0 36159 0.11 102
998 And Now for Something Completely Different 1971 7.6 NaN 27967 NaN 88
999 Lage Raho Munna Bhai 2006 8.1 NaN 40366 2.22 144
- DataFrame 타입 확인
print(movies.dtypes)> Result
movie object
year int32
imdb float64
metascore float64
votes int32
us_grossMillions float64
timeMin int32
dtype: object
- 결측치 확인(결측치 위치 / 데이터 누락치)
print(movies.isnull().sum())> Result
movie 0
year 0
imdb 0
metascore 166
votes 0
us_grossMillions 157
timeMin 0
dtype: int64
- 결측치 데이터 변경(NaN > None Given / NaN > 공백)
movies.metascore = movies.metascore.fillna("None Given")
movies.us_grossMillions = movies.us_grossMillions.fillna("")
print(movies['metascore'])
print(movies['us_grossMillions'])> Result
0 82
1 78
2 96
3 90
4 58
...
995 None Given
996 None Given
997 75
998 None Given
999 None Given
Name: metascore, Length: 1000, dtype: object
0 165.36
1 159.18
2 53.37
3
4 0.35
...
995
996
997 0.11
998
999 2.22
Name: us_grossMillions, Length: 1000, dtype: object
- CSV 저장
movies.to_csv('movies.csv')
- 최종 결과물
'Python_Crawling > Crawling' 카테고리의 다른 글
| [패스트캠퍼스]04. lxml 사용 기초 스크랩핑 B <수정코드> (0) | 2020.07.19 |
|---|---|
| [패스트캠퍼스]04. lxml 사용 기초 스크랩핑 A <수정코드> (0) | 2020.07.05 |
| [Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 2 (0) | 2020.03.29 |
| [Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 1 (0) | 2020.03.29 |
| [Naver]네이버 메일 제목 가져오기 - 클립보드 사용 (0) | 2020.03.08 |



