반응형
파이썬 웹 개발
https://www.fastcampus.co.kr/dev_online_pyweb
파이썬 웹 개발 올인원 패키지 Online. | 패스트캠퍼스
성인 교육 서비스 기업, 패스트캠퍼스는 개인과 조직의 실질적인 '업(業)'의 성장을 돕고자 모든 종류의 교육 콘텐츠 서비스를 제공하는 대한민국 No. 1 교육 서비스 회사입니다.
www.fastcampus.co.kr
기존 코드 오류>
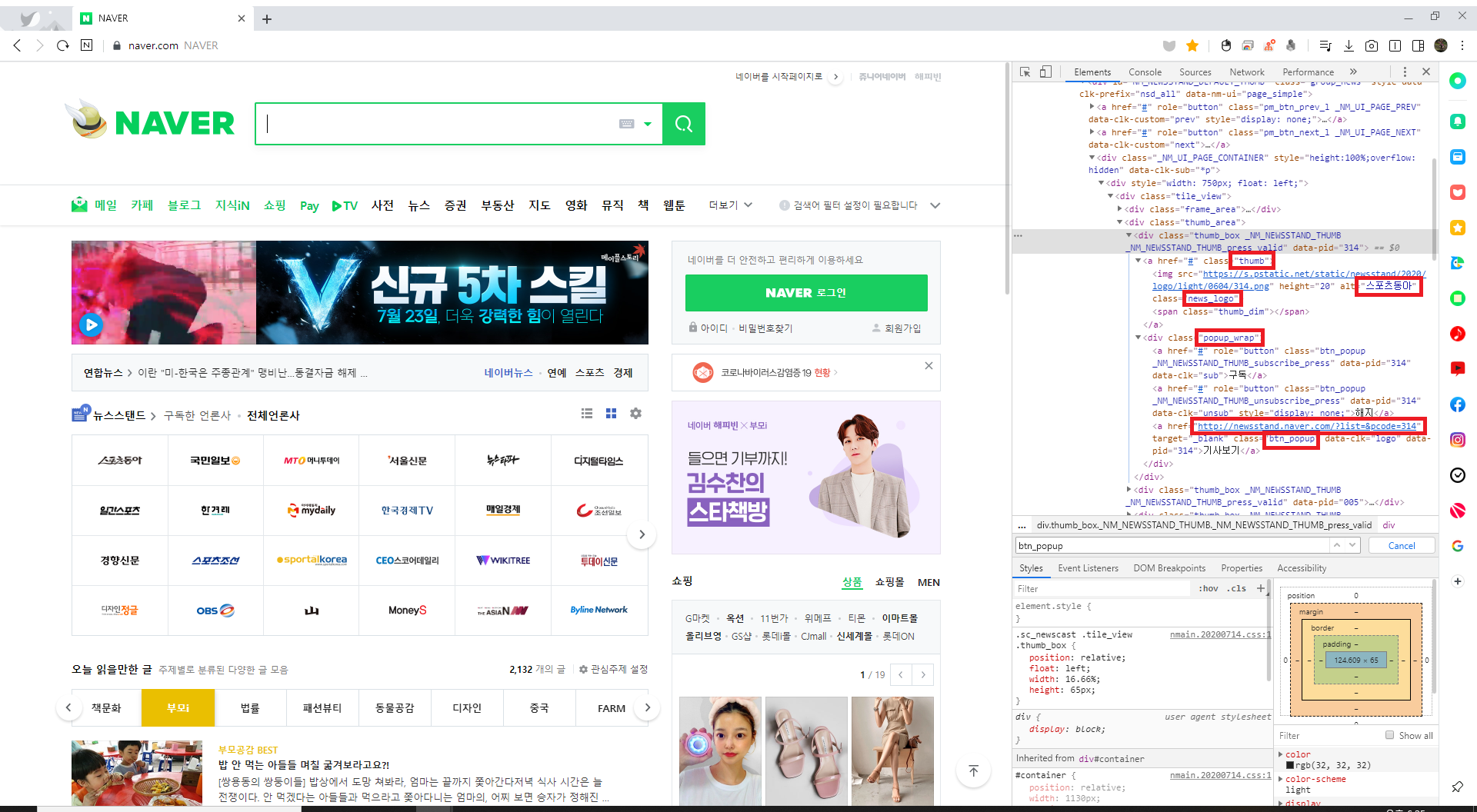
네이버 메인 사이트 뉴스 개편으로 인하여 사이트 구조 변경
네이버 구조 확인>
기존에 강의 동영상과 다르게 클래스가 변경된 것을 확인할 수 있음.
강의와는 다르게 구조가 2개로 나누어져 있는 것을 확인할 수 있음.
이에 함수를 2개 구성해서 리스트에서 딕셔너리를 변환 후 처리하는 것으로 결정
기존 코드>
import requests
from lxml.html import fromstring, tostring
def main():
"""
네이버 메인 뉴스 스탠드 스크랩핑 메인 함수
"""
# 세션 사용
session = requests.Session()
# 스크랩핑 대상 URL
response = session.get('http://www.naver.com/')
# 신문사 정보 딕셔너리 획득
urls = scrape_news_list_page(response)
# 딕셔너리 확인
# print(urls)
# 결과 출력
for name, url in urls.items():
print(name, url)
def scrape_news_list_page(response):
# URL 딕셔너리 선언
urls = {}
# 태그 정보 문자열 저장
root = fromstring(response.content)
# 문서내 경로 절대 경로 변환
root.make_links_absolute(response.url)
for a in root.xpath('//ul[@class="api_list"]/li[@class="api_item"]/a[@class="api_link"]'):
# a 구조 확인
# print(dir(a))
# a 문자열 출력
# print(tostring(a, pretty_print=True))
# 신문사, 링크 추출 함수
name, url = extract_contents(a)
# 딕셔너리 삽입
urls[name] = url
return urls
def extract_contents(dom):
# 링크 주소
link = dom.get('href')
# dom 구조 확인
# print(tostring(dom, pretty_print=True))
# 신문사 명
name = dom.xpath('./img')[0].get('alt') # xpath('./img')
return name, link
# 스크랩핑 시작
if __name__ == '__main__':
main()
수정 코드>
# Section02-4
# 파이썬 크롤링 기초
# lxml 사용 기초 스크랩핑(2)
import requests
from lxml.html import fromstring, tostring
def main():
"""
네이버 메인 뉴스 스탠드 스크랩핑 메인 함수
"""
# 세션 사용 권장
session = requests.Session()
# 스크랩핑 대상 URL
response = session.get("https://www.naver.com/") # Get, Post
# 신문사 링크 리스트 획득
newspaper_name = scrape_newspaper_name(response) # 신문사 이름
newspaper_url = scrape_newspaper_urls(response) # 신문사 URL
# 딕셔너리 생성
news_dic = {name: value for name, value in zip(newspaper_name, newspaper_url)}
# 결과 출력
for name, url in news_dic.items():
print(name, url)
def scrape_newspaper_name(response):
newspaper_name = []
# 태그 정보 문자열 저장
root = fromstring(response.content)
# 신문사명
for a in root.xpath(
'//div[@class="thumb_area"]/div[@class="thumb_box _NM_NEWSSTAND_THUMB _NM_NEWSSTAND_THUMB_press_valid"]/a[@class="thumb"]'
):
# a 구조 확인
# print(a)
# a 문자열 출력
# print(tostring(a, pretty_print=True))
name = a.xpath("./img")[0].get("alt")
newspaper_name.append(name)
return newspaper_name
def scrape_newspaper_urls(response):
# URL 리스트 선언
newspaper_urls = []
# 태그 정보 문자열 저장
root = fromstring(response.content)
# 문서내 경로 절대 경로 변환
# root.make_links_absolute(response.url)
for a in root.cssselect(".thumb_box > .popup_wrap > a.btn_popup"):
# 링크
url = a.get("href")
# class 중복으로 인한 # 제거 방법
if len(url) >= 2:
# 리스트 삽입
newspaper_urls.append(url)
else:
pass
return newspaper_urls
# 스크랩핑 시작
if __name__ == "__main__":
main()
결과물>
스포츠서울 http://newsstand.naver.com/?list=&pcode=073
한국경제TV http://newsstand.naver.com/?list=&pcode=215
연합뉴스TV http://newsstand.naver.com/?list=&pcode=422
블로터 http://newsstand.naver.com/?list=&pcode=293
뉴스타파 http://newsstand.naver.com/?list=&pcode=930
국민일보 http://newsstand.naver.com/?list=&pcode=005
이데일리 http://newsstand.naver.com/?list=&pcode=018
지지통신 http://newsstand.naver.com/?list=&pcode=376
MBC http://newsstand.naver.com/?list=&pcode=214
스포츠조선 http://newsstand.naver.com/?list=&pcode=076
JTBC http://newsstand.naver.com/?list=&pcode=904
스포탈코리아 http://newsstand.naver.com/?list=&pcode=139
KBS World http://newsstand.naver.com/?list=&pcode=326
KBS http://newsstand.naver.com/?list=&pcode=056
데일리안 http://newsstand.naver.com/?list=&pcode=368
TV조선 http://newsstand.naver.com/?list=&pcode=902
TheAsiaN http://newsstand.naver.com/?list=&pcode=949
데일리한국 http://newsstand.naver.com/?list=&pcode=042
MONEY http://newsstand.naver.com/?list=&pcode=806
KNN http://newsstand.naver.com/?list=&pcode=906
르몽드 디플로마티크 http://newsstand.naver.com/?list=&pcode=915
더팩트 http://newsstand.naver.com/?list=&pcode=536
이뉴스투데이 http://newsstand.naver.com/?list=&pcode=964
브릿지경제 http://newsstand.naver.com/?list=&pcode=939반응형
'Python_Crawling > Crawling' 카테고리의 다른 글
| [패스트캠퍼스]Selenium 사용 실습 <수정코드> (0) | 2020.08.08 |
|---|---|
| [패스트캠퍼스]04. lxml 사용 기초 스크랩핑 A <수정코드> (0) | 2020.07.05 |
| [Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 3 (0) | 2020.03.29 |
| [Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 2 (0) | 2020.03.29 |
| [Crawling]imDB(인터넷 영화 데이터 베이스) Tutorial - 1 (0) | 2020.03.29 |



