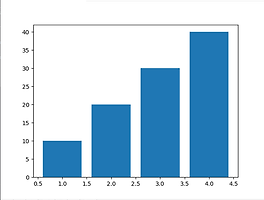
 Python Matplotlib - 세로 막대 그래프 기초 1
1. Matplotlib자료를 차트나 플롯 형식으로 시각화 패키지다양한 시각화 기능 제공 2. 세로 막대 그래프집단간의 차이를 표현평균 막대 그래프 3. 설치pip install matplotlib 4. Pyplot 모듈 로드from matplotlib import pyplot 5. 기본 구조from matplotlib import pyplot Reference_axis = [1, 2, 3, 4] Value_axis = [10, 20, 30 , 40] pyplot.figure() pyplot.bar(Reference_axis, Value_axis) pyplot.show() pyplot.close() 6. 기본 구조 정리- 기준축 DB 설정(X축)Reference_axis = [1, 2, 3, 4] - 데..
Python Matplotlib - 세로 막대 그래프 기초 1
1. Matplotlib자료를 차트나 플롯 형식으로 시각화 패키지다양한 시각화 기능 제공 2. 세로 막대 그래프집단간의 차이를 표현평균 막대 그래프 3. 설치pip install matplotlib 4. Pyplot 모듈 로드from matplotlib import pyplot 5. 기본 구조from matplotlib import pyplot Reference_axis = [1, 2, 3, 4] Value_axis = [10, 20, 30 , 40] pyplot.figure() pyplot.bar(Reference_axis, Value_axis) pyplot.show() pyplot.close() 6. 기본 구조 정리- 기준축 DB 설정(X축)Reference_axis = [1, 2, 3, 4] - 데..
 190508>Korea News keyword wordcloud
현재 뉴스에서 많이 사용중인 키워드 분석 시각화 모듈WordCloud를 활용하여 시각화190508 키워드 분석 시각화 현재 키워드>'사건': 66, '경찰': 55, '기자': 51, '서울': 49, '규제': 47, '검찰': 47, '마을': 46, '한국': 43, '의원': 40, '신도시': 37, '원내대표': 34, '정부': 34, '시장': 33, '굴뚝': 33, '수사': 32, '지난': 30, '경제': 30, '현재': 29, '노루': 29, '선거': 28, '무단': 28, '대한': 28, '배포': 27, '금지': 27, '지정': 27, '무섬': 27, '대표': 26, '지역': 26, '부동산': 26, '국회': 25, '혁신': 24, '뉴스': 24, '..
190508>Korea News keyword wordcloud
현재 뉴스에서 많이 사용중인 키워드 분석 시각화 모듈WordCloud를 활용하여 시각화190508 키워드 분석 시각화 현재 키워드>'사건': 66, '경찰': 55, '기자': 51, '서울': 49, '규제': 47, '검찰': 47, '마을': 46, '한국': 43, '의원': 40, '신도시': 37, '원내대표': 34, '정부': 34, '시장': 33, '굴뚝': 33, '수사': 32, '지난': 30, '경제': 30, '현재': 29, '노루': 29, '선거': 28, '무단': 28, '대한': 28, '배포': 27, '금지': 27, '지정': 27, '무섬': 27, '대표': 26, '지역': 26, '부동산': 26, '국회': 25, '혁신': 24, '뉴스': 24, '..
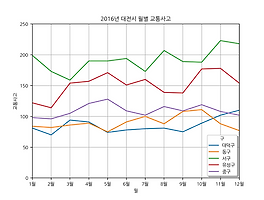 Python Matplotlib - 선 그래프 한글 폰트 적용
1. 그래프 단계(셀로판지 개념)1단계 : 배경 설정(축)2단계 : 그래프 추가(점, 막대, 선)3단계 : 설정 추가(축 범위, 색, 표식) 2. Sample Data BaseDaedeok = [81, 70, 94, 91, 74, 78, 80, 81, 75, 89, 102, 110] Donggu = [84, 82, 86, 89, 75, 91, 100, 88, 108, 111, 88, 77] Seogu = [199, 173, 159, 190, 190, 194, 173, 207, 189, 188, 223, 218] Yuseong = [122, 114, 154, 157, 171, 151, 160, 139, 138, 177, 178, 154] Junggu = [98, 96, 105, 121, 128, 109, ..
Python Matplotlib - 선 그래프 한글 폰트 적용
1. 그래프 단계(셀로판지 개념)1단계 : 배경 설정(축)2단계 : 그래프 추가(점, 막대, 선)3단계 : 설정 추가(축 범위, 색, 표식) 2. Sample Data BaseDaedeok = [81, 70, 94, 91, 74, 78, 80, 81, 75, 89, 102, 110] Donggu = [84, 82, 86, 89, 75, 91, 100, 88, 108, 111, 88, 77] Seogu = [199, 173, 159, 190, 190, 194, 173, 207, 189, 188, 223, 218] Yuseong = [122, 114, 154, 157, 171, 151, 160, 139, 138, 177, 178, 154] Junggu = [98, 96, 105, 121, 128, 109, ..
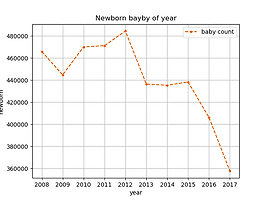 Python Matplotlib - 선 그래프 기초 2
1. 그래프 단계(셀로판지 개념)1단계 : 배경 설정(축)2단계 : 그래프 추가(점, 막대, 선)3단계 : 설정 추가(축 범위, 색, 표식) 2. Sample Data Basenewborn = [465892, 444849, 470171, 471265, 484550, 436455, 435435, 438420, 406243, 357771] year = [2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017] 3. Sample Codefrom matplotlib import pyplot newborn = [465892, 444849, 470171, 471265, 484550, 436455, 435435, 438420, 406243, 357771] year =..
Python Matplotlib - 선 그래프 기초 2
1. 그래프 단계(셀로판지 개념)1단계 : 배경 설정(축)2단계 : 그래프 추가(점, 막대, 선)3단계 : 설정 추가(축 범위, 색, 표식) 2. Sample Data Basenewborn = [465892, 444849, 470171, 471265, 484550, 436455, 435435, 438420, 406243, 357771] year = [2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017] 3. Sample Codefrom matplotlib import pyplot newborn = [465892, 444849, 470171, 471265, 484550, 436455, 435435, 438420, 406243, 357771] year =..







