반응형
1. Sample Data
# 딕셔너리 성적 리스트
grade_dic = {
'국어': [98, 88, 68, 64, 120],
'영어': [None, 90, 60, 20, 50],
'수학': [90, 70, None, 31, None],
'과학': [120, 50, None, 60, 88]
}
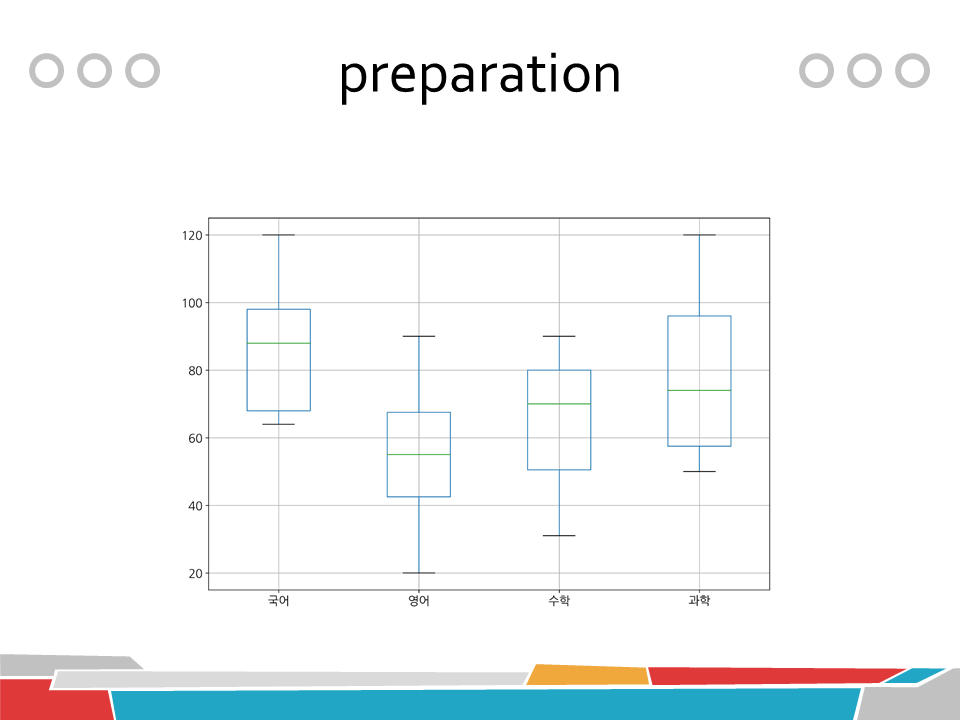
2. 상자 수염 그림으로 이상치 확인하기
from pandas import DataFrame
from Data import grade_dic
from print_df import print_df
from matplotlib import pyplot
from sklearn.impute import SimpleImputer
import numpy
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 상자 수염 그림 생성
pyplot.rcParams['font.family'] = 'NanumGothic'
pyplot.rcParams['font.size'] = 14
pyplot.rcParams['figure.figsize'] = (12, 8)
pyplot.figure()
df.boxplot()
pyplot.savefig('outlier.png', dpi=300)
pyplot.show()
pyplot.close()
3. 이상치 필터링
from pandas import DataFrame
from Data import grade_dic
from print_df import print_df
from matplotlib import pyplot
from sklearn.impute import SimpleImputer
import numpy
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 국어점수 이상치 필터링
filtering_outlier = df.query('국어 > 100')
print_df(filtering_outlier)
4. 인덱스 추출
from pandas import DataFrame
from Data import grade_dic
from print_df import print_df
from matplotlib import pyplot
from sklearn.impute import SimpleImputer
import numpy
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 국어점수 이상치 필터링
filtering_outlier = df.query('국어 > 100')
# 필터링 된 이상치 인덱스 추출
filtering_outlier_index = list(filtering_outlier.index)
print_df(filtering_outlier_index)
5. 결측치 변경
from pandas import DataFrame
from Data import grade_dic
from print_df import print_df
from matplotlib import pyplot
from sklearn.impute import SimpleImputer
import numpy
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 국어점수 이상치 필터링
filtering_outlier = df.query('국어 > 100')
# 필터링 된 이상치 인덱스 추출
filtering_outlier_index = list(filtering_outlier.index)
# 결측치로 변경
for i in filtering_outlier_index:
df.loc[i, '국어'] = numpy.nan
print_df(df)
6. 모든 이상치 결측치 변경
from pandas import DataFrame
from Data import grade_dic
from print_df import print_df
from matplotlib import pyplot
from sklearn.impute import SimpleImputer
import numpy
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 점수 이상치 필터링
filtering_outlier = df.query('국어 > 100')
filtering_outlier2 = df.query('과학 > 100')
# 필터링 된 이상치 인덱스 추출
filtering_outlier_index = list(filtering_outlier.index)
filtering_outlier_index2 = list(filtering_outlier2.index)
# 결측치로 변경
for i in filtering_outlier_index:
df.loc[i, '국어'] = numpy.nan
for j in filtering_outlier_index2:
df.loc[j, '과학'] = numpy.nan
print_df(df)
7. 결측치 규칙 적용 후 신규 데이터 프레임 생성
from pandas import DataFrame
from Data import grade_dic
from print_df import print_df
from matplotlib import pyplot
from sklearn.impute import SimpleImputer
import numpy
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 점수 이상치 필터링
filtering_outlier = df.query('국어 > 100')
filtering_outlier2 = df.query('과학 > 100')
# 필터링 된 이상치 인덱스 추출
filtering_outlier_index = list(filtering_outlier.index)
filtering_outlier_index2 = list(filtering_outlier2.index)
# 결측치로 변경
for i in filtering_outlier_index:
df.loc[i, '국어'] = numpy.nan
for j in filtering_outlier_index2:
df.loc[j, '과학'] = numpy.nan
# 결측치 규칙 정의
null_regulation = SimpleImputer(
missing_values=numpy.nan, strategy='most_frequent')
# 규칙 적용
df_null_regulation = null_regulation.fit_transform(df.values)
# 데이터 프레임 생성
df2 = DataFrame(df_null_regulation, index=list(
df.index), columns=list(df.columns))
print_df(df2)








반응형
'Python_Intermediate > Pandas' 카테고리의 다른 글
| [EXCEL]Excel File Data Analysis(엑셀 파일 Pandas 분석) (0) | 2020.02.15 |
|---|---|
| [Python]Data Preparation Basic(데이터 전처리 기초) 4 (0) | 2020.02.02 |
| [Python]Data Preparation Basic(데이터 전처리 기초) 3 (0) | 2020.02.01 |
| [Python]Data Preparation Basic(데이터 전처리 기초) 2 (0) | 2020.02.01 |
| [Python]Data Preparation Basic(데이터 전처리 기초) 1 (0) | 2020.01.21 |



