
• REST(Representational State Transfer)?
월드 와이드 웹과 같은 분산 하이퍼미디어 시스템을 위한 소프트웨어 아키텍처의 한 형식
•참고 : https://developers.kakao.com/
Kakao Developers_
더 나은 세상을 꿈꾸고 그것을 현실로 만드는 이를 위하여 카카오에서 앱 개발 플랫폼 서비스를 시작합니다.
developers.kakao.com
• 참고 : https://meetup.toast.com/posts/92
REST API 제대로 알고 사용하기 : TOAST Meetup
REST API 제대로 알고 사용하기
meetup.toast.com
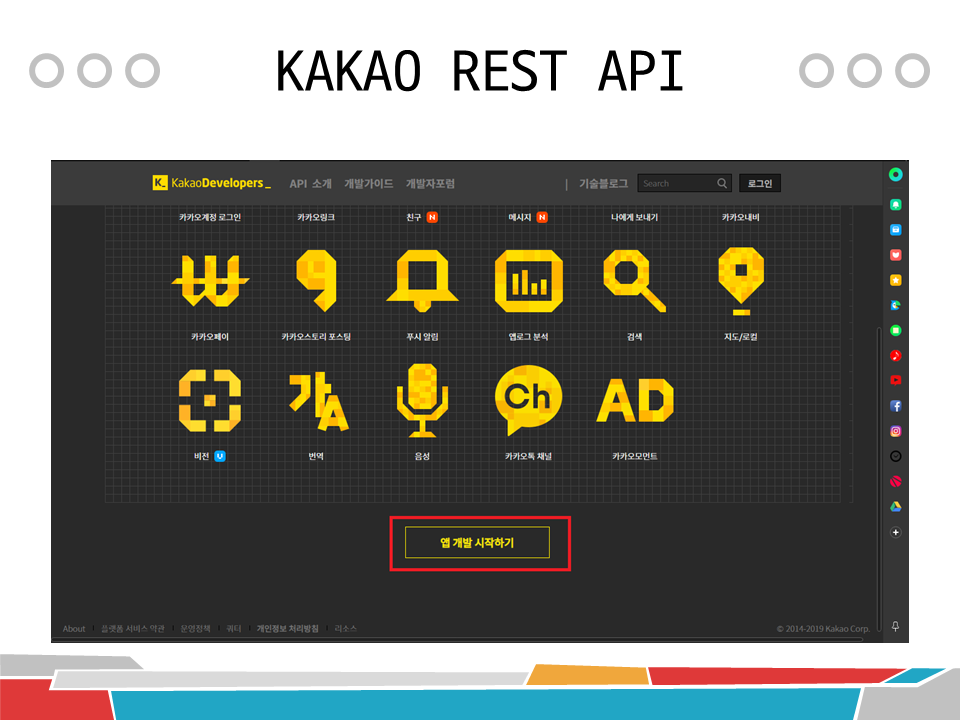
• 앱 개발 시작하기

• 앱 만들기

• 앱 이름 작성
• 회사명 작성
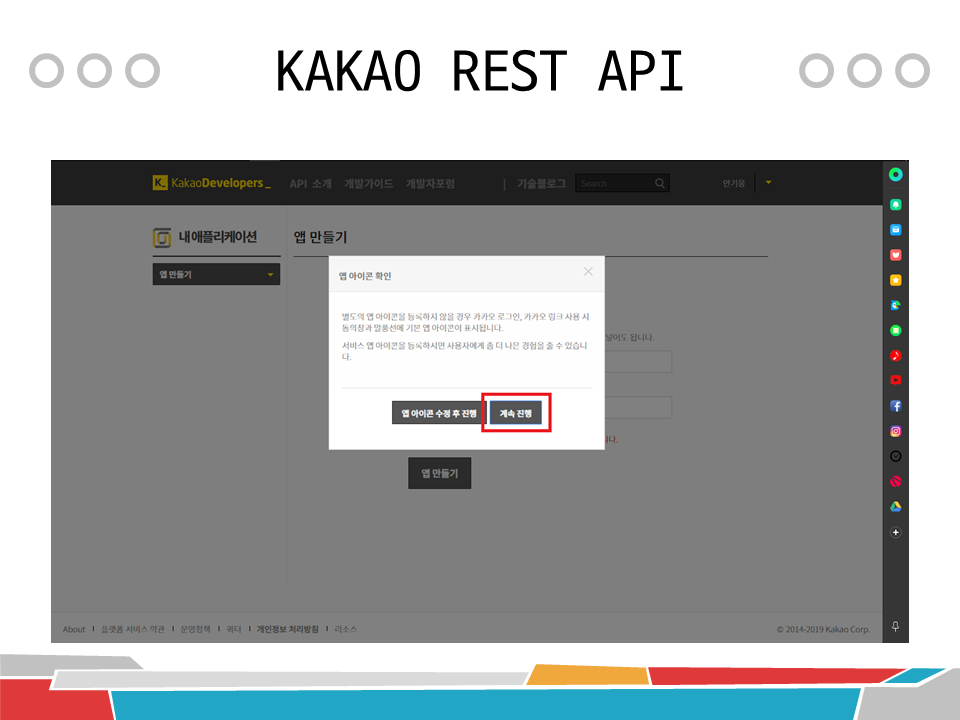
• 계속진행

• REST API 키 복사

• 설정 > 일반 > 기본정보 > 앱 키 > REST API
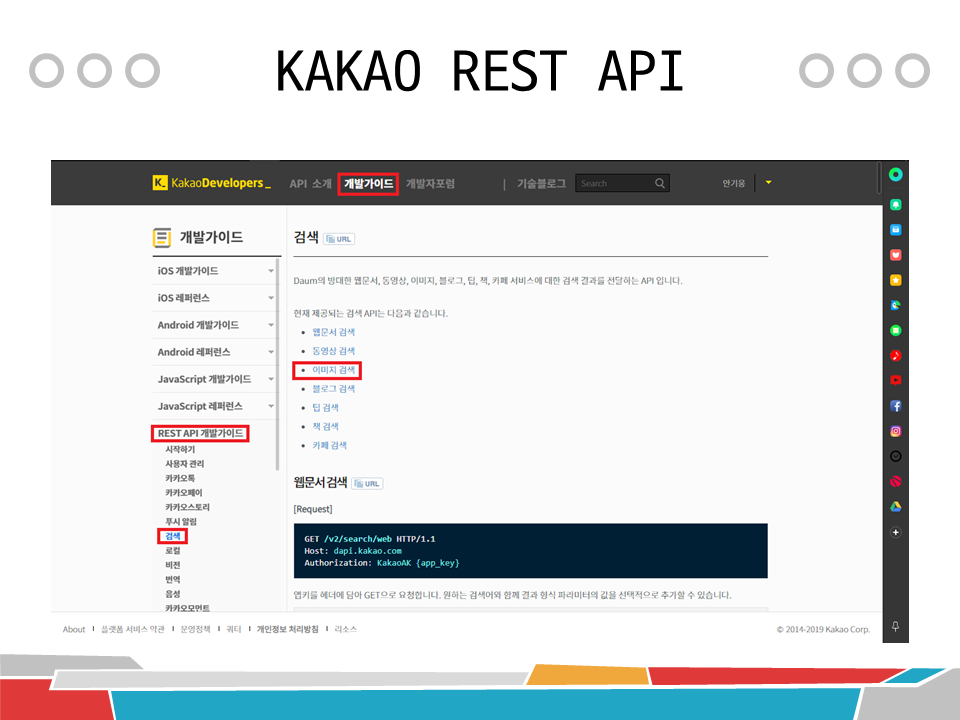
• 개발가이드 > REST API 개발가이드 > 검색 > 이미지 검색

• from Crawler import crawler
• import urllib
• import json
• import datetime as dt

|
키 |
설명 |
필수 |
타입 |
|
query |
검색을 원하는 질의어 |
O |
String |
|
sort |
결과 문서 정렬 방식 |
X (accuracy) |
accuracy (정확도순) or recency (최신순) |
|
page |
결과 페이지 번호 |
X(기본 1) |
1-50 사이 Integer |
|
size |
한 페이지에 보여질 문서의 개수 |
X(기본 80) |
1-80 사이 Integer |


|
키 |
설명 |
타입 |
|
collection |
컬렉션 |
String |
|
thumbnail_url |
이미지 썸네일 URL |
String |
|
image_url |
이미지 URL |
String |
|
width |
이미지의 가로 크기 |
Integer |
|
height |
이미지의 세로 크기 |
Integer |
|
display_sitename |
출처명 |
String |
|
doc_url |
문서 URL |
String |
|
datetime |
문서 작성시간. ISO 8601. [YYYY]-[MM]-[DD]T[hh]:[mm]:[ss].000+[tz] |
String |

• 중간 출력 결과물
{'documents':
[{'collection': 'news',
'datetime': '2019-12-14T16:30:22.000+09:00',
'display_sitename': '데일리한국',
'doc_url': 'https://cp.news.search.daum.net/p/87507491',
'height': 445,
'image_url': 'http://photo.hankooki.com/newsphoto/v001/2019/12/14/sol20191214162558_O_03_C_1.jpg',
'thumbnail_url': 'https://search1.kakaocdn.net/argon/130x130_85_c/GqRnACHOpJU',
'width': 670}]

• 필요한것은 'image_url': 'http://photo.hankooki.com/newsphoto/v001/2019/12/14/sol20191214162558_O_03_C_1.jpg'

• URL을 주소창에 복사 > 붙여넣기 시 사진이 정상적으로 출력


• 중간 출력 결과물
Index no : 0 / Itme : {'collection': 'news', 'datetime': '2019-12-14T16:30:22.000+09:00', 'display_sitename': '데일리한국', 'doc_url': 'https://cp.news.search.daum.net/p/87507491', 'height': 445, 'image_url': 'http://photo.hankooki.com/newsphoto/v001/2019/12/14/sol20191214162558_O_03_C_1.jpg', 'thumbnail_url': 'https://search1.kakaocdn.net/argon/130x130_85_c/GqRnACHOpJU', 'width': 670}
}Index no : 1 / Itme : {'collection': 'news', 'datetime': '2019-12-14T16:39:02.000+09:00', 'display_sitename': '스타투데이', 'doc_url': 'http://v.media.daum.net/v/20191214163902707', 'height': 680, 'image_url': 'https://t1.daumcdn.net/news/201912/14/startoday/20191214163904819jrgi.jpg', 'thumbnail_url': 'https://search2.kakaocdn.net/argon/130x130_85_c/DROmALKpowt', 'width': 630}
}Index no : 2 / Itme : {'collection': 'news', 'datetime': '2019-12-13T13:46:01.000+09:00', 'display_sitename': '스포츠조선', 'doc_url': 'http://v.media.daum.net/v/20191213134601107', 'height': 640, 'image_url': 'https://t1.daumcdn.net/news/201912/13/SpoChosun/20191213135850847atpf.jpg', 'thumbnail_url': 'https://search2.kakaocdn.net/argon/130x130_85_c/1VPwIJQNU7p', 'width': 640}

• 파일명 정상적으로 출력(검색어_검색날짜_사진번호.jpg)

• 최종 진행


• 사진이 정상적으로 저장됨
• API 발표 Code
from Crawler import crawler
import urllib
import json
import datetime as dt
page = map(int, input('검색할 최소페이지 최대페이지의 범위를 입력하세요 : ').split())
page_list = list(page)
page_min = page_list[0]
page_max = page_list[1]
for num in range(page_min, page_max):
params_query = input('이미지를 저장할 키워드를 입력하세요 : ')
params = {'page': num, 'size': '80', 'query': params_query}
query = urllib.parse.urlencode(params)
site_url = "https://dapi.kakao.com/v2/search/image?" + query
result = crawler.get(site_url)
data = json.loads(result)
documents = data['documents']
for idx, item in enumerate(documents):
fname = params_query + '_' + dt.datetime.now().strftime('%y%m%d_') + \
'%02d.png' % idx
ok = crawler.download(item['image_url'], filename=fname)
print('{0} (이)가 저장되었습니다.'.format(ok))'Python_Intermediate > API' 카테고리의 다른 글
| [API]영화진흥원 박스오피스 순위 분위 (0) | 2020.02.11 |
|---|---|
| [API]KAKAO API 발급 방법(카카오 API) (0) | 2019.12.15 |
| API - Naver searching call example (0) | 2019.08.21 |


