from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# Chrome Browser 옵션 사용
options = Options()
# Chrome Browser 숨기기 모드
options.add_argument('headless')
# chromedriver 및 options
driver = webdriver.Chrome(executable_path='C:\\chromedriver\\chromedriver', options=options)
# 3초 대기
driver.implicitly_wait(3)
# 자동화 대상 Site
driver.get('http://quotes.toscrape.com/')
# login button click
site_login = driver.find_element_by_xpath('/html/body/div/div[1]/div[2]/p/a')
site_login.click()
# login id / pw 지정
login_id = 'ankiwoong'
login_pw = 'ankiwoong'
# id login
id = driver.find_element_by_name('username').send_keys(login_id)
# pw login
pw = driver.find_element_by_name('password').send_keys(login_pw)
# login button click
login_click = driver.find_element_by_xpath('/html/body/div/form/input[2]')
login_click.click()
# 페이지의 elements 모두 가져오기
html = driver.page_source
# BeautifulSoup 사용
soup = BeautifulSoup(html, 'html.parser')
# 명언
notices_s = soup.select('div.col-md-8 > div.quote > span.text')
# 위인
notices_e = soup.select('div.col-md-8 > div.quote > span > small.author')
# 빈 리스트 생성
s_list = []
e_list = []
# 명언 가져오기
for i in notices_s:
s_list.append(i.text.strip())
# 위인 가져오기
for j in notices_e:
e_list.append(j.text)
# 명언 리스트와 위인 리스트의 길이를 비교하여 길이가 같으면 파일 생성
if len(s_list) == len(e_list):
f = open('print.txt', 'w', encoding='utf-8')
for a in range(len(s_list)):
data = s_list[a] + ' by ' + e_list[a] + '\n'
f.write(data)
f.close()
else:
print('Error')
# driver 종료(메모리 초기화)
driver.quit()
1. 로그인 후 페이지가 나온다는 가정하에 코드 작성
2. headless 옵션을 사용하여 크롬 히든 모드로 크롤링 작업
3. 크롬 개발자 모드 실행(F12)
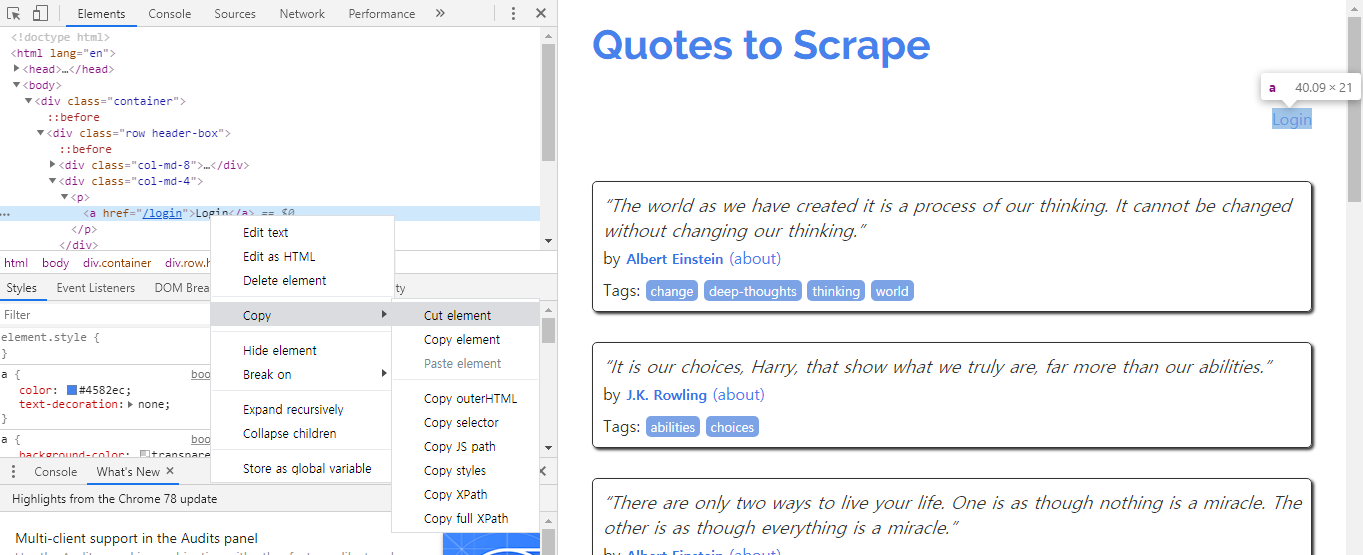
Login > Select 모드로 클릭 > 우측 버튼 > Copy > Copy XPath
4.
site_login = driver.find_element_by_xpath('/html/body/div/div[1]/div[2]/p/a')
site_login.click()
5. 로그인 아이디 / 패스워드 설정
login_id = 'ankiwoong'
login_pw = 'ankiwoong'
6.
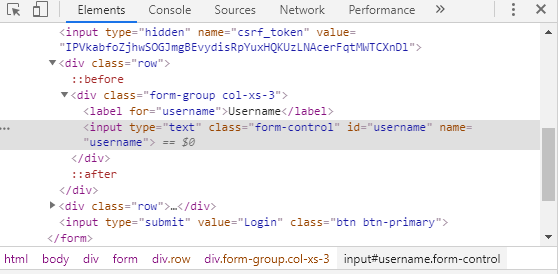
7. id 부분을 보고 pw 부분을 보면 비슷한 부분을 찾을 수 있음.
id="username"
id="password"
이 두개를 가지고 키 값을 전달하여 로그인 시킨다.
8.
# id login
id = driver.find_element_by_name('username').send_keys(login_id)
# pw login
pw = driver.find_element_by_name('password').send_keys(login_pw)
9. 3번 부분과 동일하게 클릭 XPath를 찾아 클릭
login_click = driver.find_element_by_xpath('/html/body/div/form/input[2]')
login_click.click()
10. html 가져오기
html = driver.page_source
11. BS4 사용
soup = BeautifulSoup(html, 'html.parser')
12. 명언 파트 가져오기
notices_s = soup.select('div.col-md-8 > div.quote > span.text')
s_list = []
for i in notices_s:
s_list.append(i.text.strip())['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”', '“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”', "“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”", '“Try not to become a man of success. Rather become a man of value.”', '“It is better to be hated for what you are than to be loved for what you are not.”', "“I have not failed. I've just found 10,000 ways that won't work.”", "“A woman is like a tea bag; you never know how strong it is until it's in hot water.”", '“A day without sunshine is like, you know, night.”']
12. 위인 파트 가져오기
notices_e = soup.select('div.col-md-8 > div.quote > span > small.author')
e_list = []
for j in notices_e:
e_list.append(j.text)['Albert Einstein', 'J.K. Rowling', 'Albert Einstein', 'Jane Austen', 'Marilyn Monroe', 'Albert Einstein', 'André Gide', 'Thomas A. Edison', 'Eleanor Roosevelt', 'Steve Martin']
13. 명언 + 위인 txt 파일 생성
# 명언 리스트와 위인 리스트의 길이를 비교하여 길이가 같으면 파일 생성
if len(s_list) == len(e_list):
f = open('print.txt', 'w', encoding='utf-8')
for a in range(len(s_list)):
data = s_list[a] + ' by ' + e_list[a] + '\n'
f.write(data)
f.close()
else:
print('Error')명언 리스트와 위인 리스트의 길이가 같지 않으면 잘못된 크롤링이므로 Error 출력
두개의 길이가 같으면 정확한 크롤링으므로 파일을 생성
14. 출력물 확인
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” by Albert Einstein
“It is our choices, Harry, that show what we truly are, far more than our abilities.” by J.K. Rowling
“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” by Albert Einstein
“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.” by Jane Austen
“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.” by Marilyn Monroe
“Try not to become a man of success. Rather become a man of value.” by Albert Einstein
“It is better to be hated for what you are than to be loved for what you are not.” by André Gide
“I have not failed. I've just found 10,000 ways that won't work.” by Thomas A. Edison
“A woman is like a tea bag; you never know how strong it is until it's in hot water.” by Eleanor Roosevelt
“A day without sunshine is like, you know, night.” by Steve Martin
15.
'Python_Crawling > Crawling' 카테고리의 다른 글
| [Crawling]Python Study - PPT Presentation Material - 1 (0) | 2019.12.16 |
|---|---|
| [Study Group]Title + Price 가져오기(Crawling 후 CSV File 저장) (0) | 2019.11.25 |
| Naver News WordCloud 2 (0) | 2019.06.04 |
| Naver News WordCloud 1 (0) | 2019.06.04 |
| Python - 한국기상청 도시별 현재 날씨 정보 분석 후 csv 저장 (0) | 2019.05.22 |


