Python_Intermediate/Pandas
[Pandas]Python Study - PPT Presentation Material - DataFrame
AnKiWoong
2020. 1. 12. 18:36
반응형

• 데이터가 크다?
-행이 많다는 의미
-> 100명의 데이터가 10만명의 데이터가 될 경우 처리시 하드웨어 사양을 높이거나 하둡(분산처리) 구축
행이 늘어나더라도 분석 기술 측면에서 별다른 차이가 없다.


• 데이터가 크다?
-열이 많다는 의미
-> 데이터 분석은 변수들 간의 관계를 다룸(학점 - 연봉의 관계 / 전공 – 연봉의 관계)
변수를 조합할 수 있는 경우의 수가 증가 의미
단순한 분석 방법으로는 해결이 힘들다.
여러 변수의 영향을 동시에 고려할 수 있는 복잡한 분석 방법을 활용
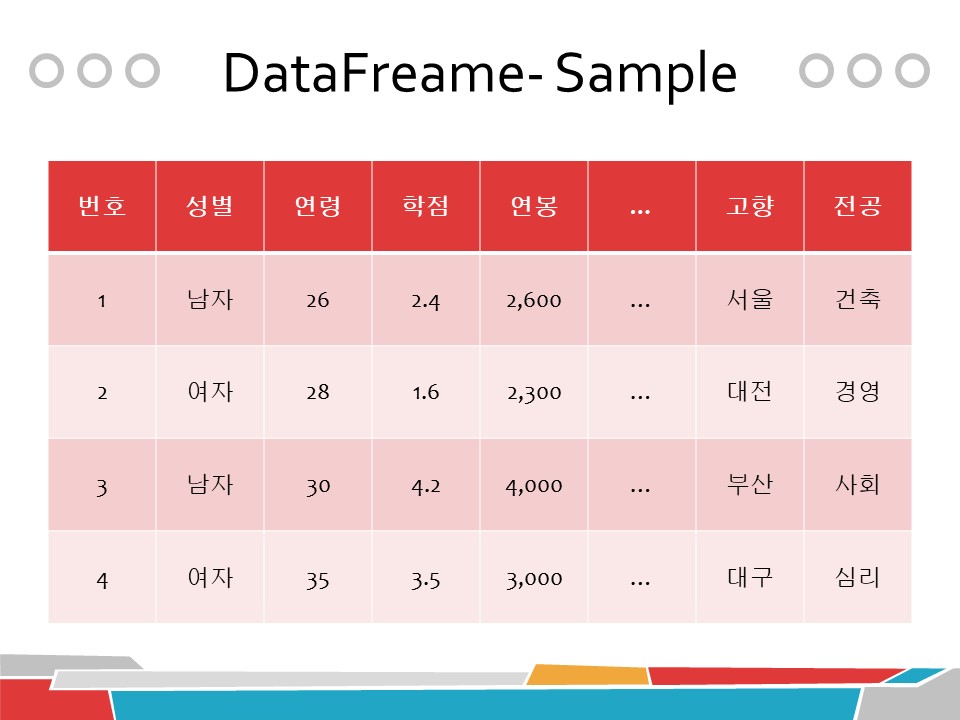

# 성적 리스트
# Sample Data List
# 2차원 성적 리스트
grade_list = [ # 국 영 수 과
[98, None, 68, 64], # 노진구
[88, 90, 60, 20], # 퉁퉁이
[90, 70, None, None], # 비실이
[62, 70, 18, 60], # 이슬이
[120, 50, None, 60] # 도라에몽
]
# 딕셔너리 성적 리스트
grade_dic = {
'국어': [98, 88, 68, 64, 120],
'영어': [None, 90, 60, 20, 50],
'수학': [90, 70, None, 31, None],
'과학': [120, 50, None, 60, 88]
}
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# List -> DataFrame
# None(값이 없음) -> NaN
# Missing
df = DataFrame(grade_list)
print(df)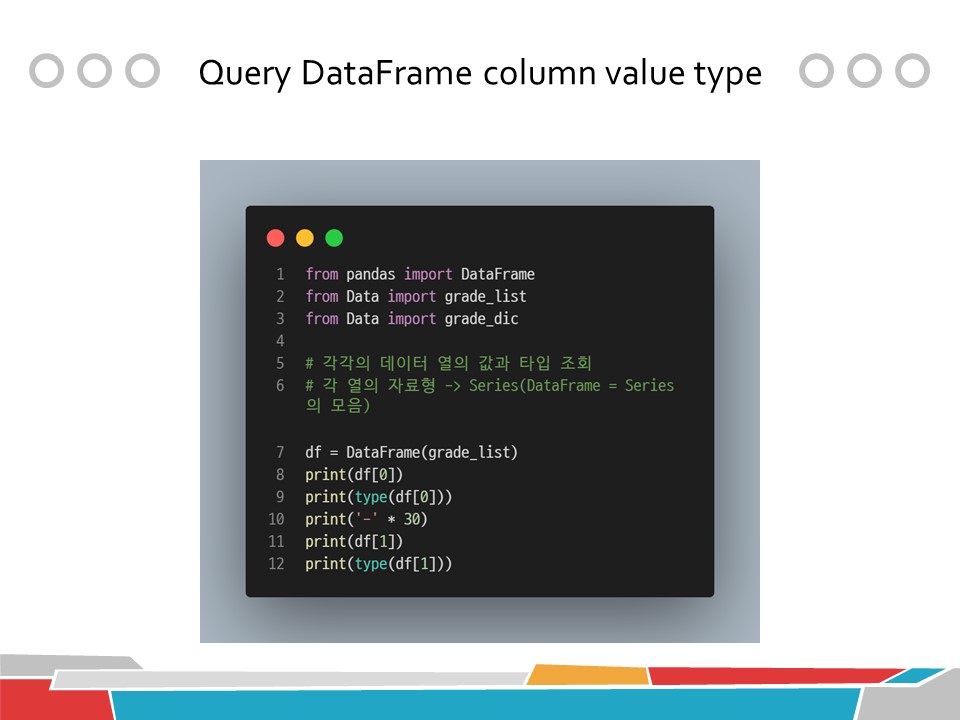
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 각각의 데이터 열의 값과 타입 조회
# 각 열의 자료형 -> Series(DataFrame = Series의 모음)
df = DataFrame(grade_list)
print(df[0])
print(type(df[0]))
print('-' * 30)
print(df[1])
print(type(df[1]))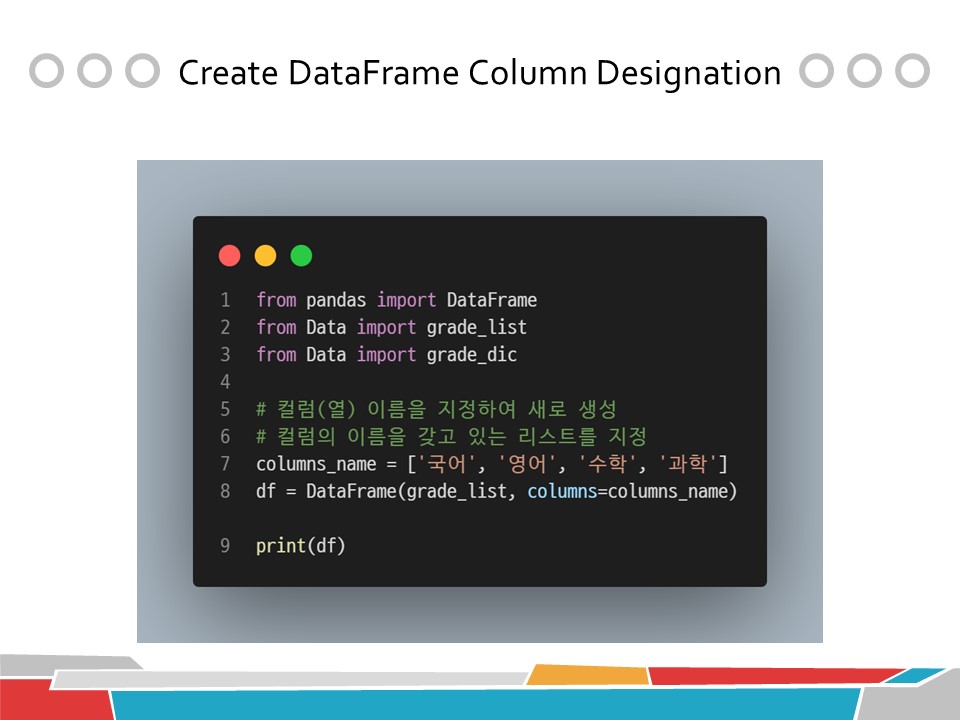
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 컬럼(열) 이름을 지정하여 새로 생성
# 컬럼의 이름을 갖고 있는 리스트를 지정
columns_name = ['국어', '영어', '수학', '과학']
df = DataFrame(grade_list, columns=columns_name)
print(df)
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 각각의 데이터 열의 값 조회
# 컬럼 이름이 지정되면 번호로 접근할 수 없다.
columns_name = ['국어', '영어', '수학', '과학']
df = DataFrame(grade_list, columns=columns_name)
print(df['국어'])
print('-' * 30)
print(df['영어'])
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 인덱스(행) 이름을 지정하여 생성
# 인덱스의 이름을 갖고 있는 리스트를 지정
index_names = ['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽']
df = DataFrame(grade_list, index=index_names)
print(df)
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 인덱스와 컬럼이름 모두 지정
columns_name = ['국어', '영어', '수학', '과학']
index_name = ['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽']
df = DataFrame(grade_list, index=index_name, columns=columns_name)
print(df)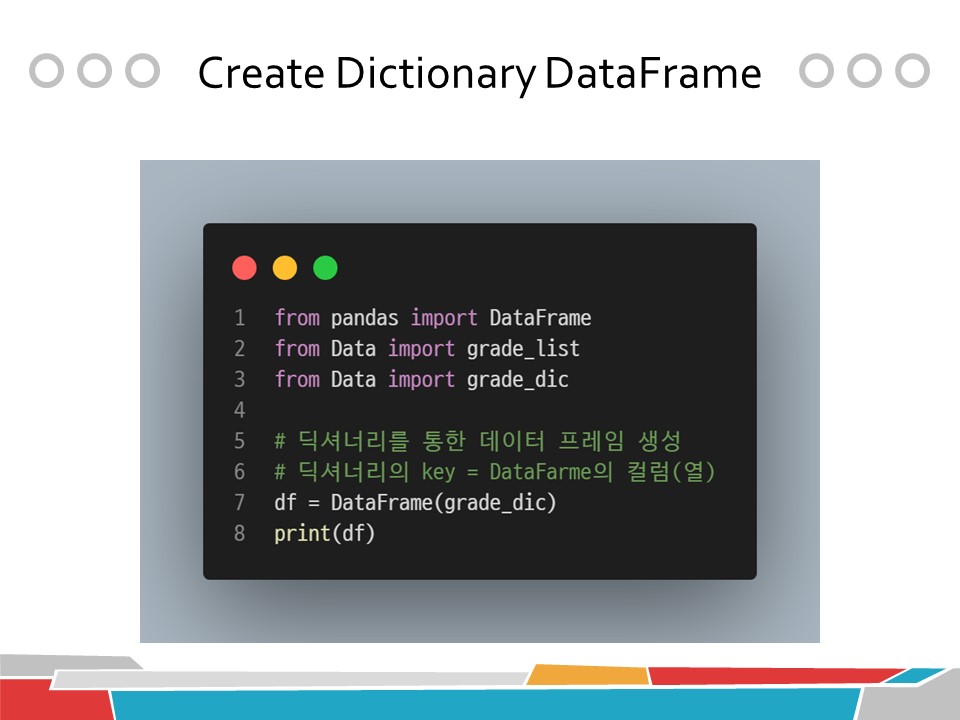
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 딕셔너리를 통한 데이터 프레임 생성
# 딕셔너리의 key = DataFarme의 컬럼(열)
df = DataFrame(grade_dic)
print(df)
from pandas import DataFrame
from Data import grade_list
from Data import grade_dic
# 인덱스 이름을 지정한 데이터 프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
print(df)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 열을 기준으로 데이터 타입 확인
print(df.dtypes)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 열을 기준으로 데이터 값 확인
print(df['국어'])
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 열의 값 numpy 배열로 추출
array = df['국어'].values
print(type(array))
print(array)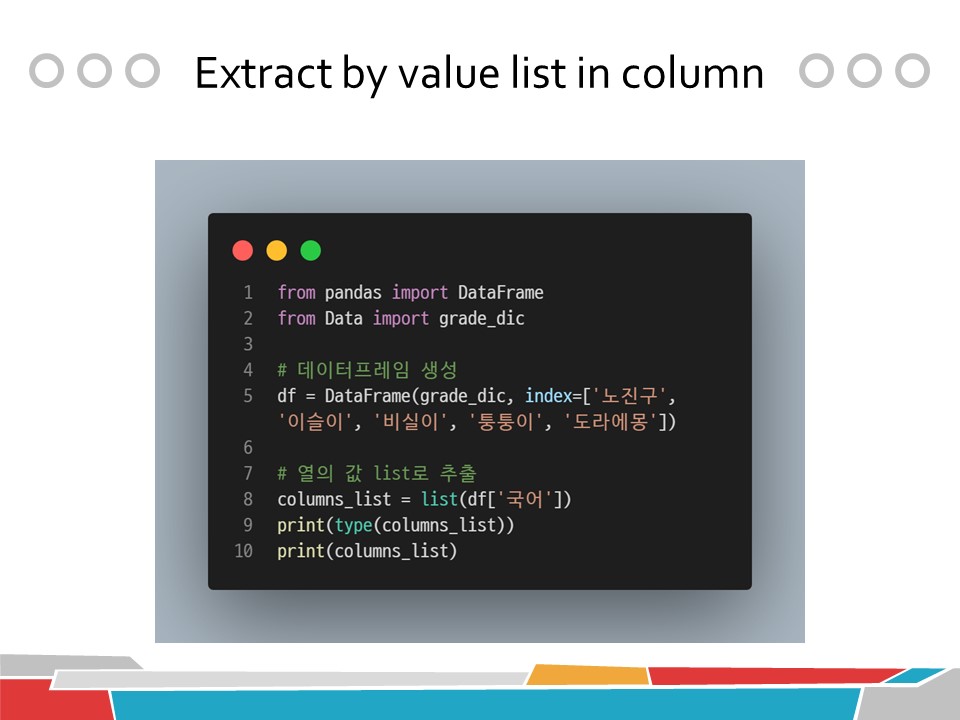
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 열의 값 list로 추출
columns_list = list(df['국어'])
print(type(columns_list))
print(columns_list)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 하나의 행에 속한 모든 데이터 추출
column = df.loc['노진구']
print(column)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# Series Return
# DataFrame은 Series의 모음
column = df.loc['노진구']
print(type(column))
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 행의 값들을 numpy 배열로 추출
column = df.loc['노진구']
array = column.values
print(type(array))
print(array)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 행의 값들을 numpy 배열로 추출
column = df.loc['노진구']
column_list = list(column)
print(type(column_list))
print(column_list)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 열 -> 행 순으로 접근
print('노진구의 국어 점수는 %d 점 입니다.' % df['국어']['노진구'])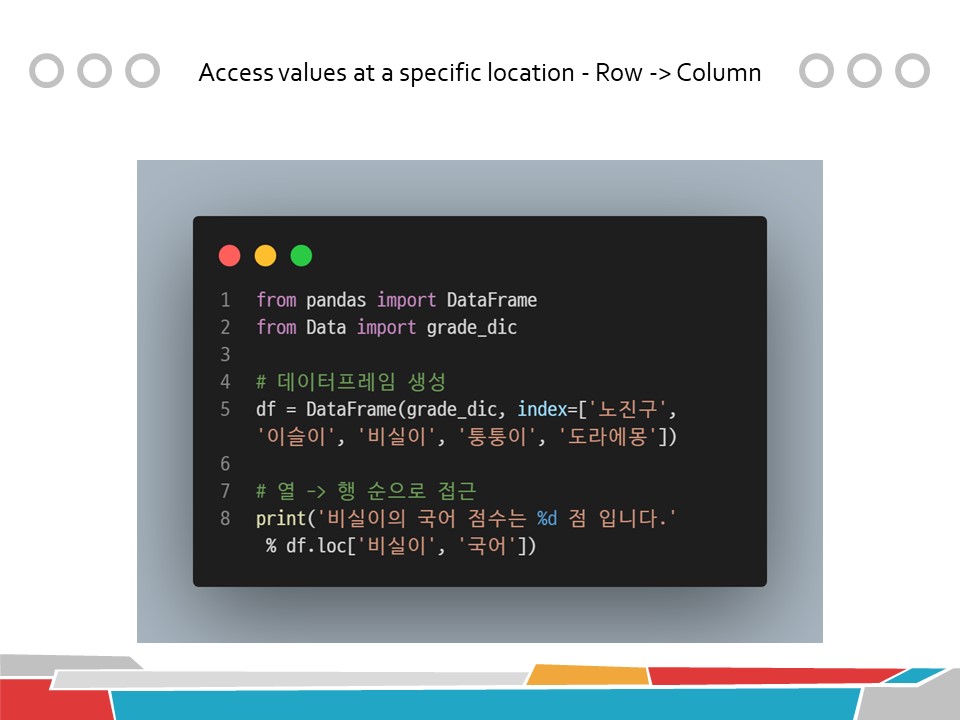
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 열 -> 행 순으로 접근
print('비실이의 국어 점수는 %d 점 입니다.' % df.loc['비실이', '국어'])
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 특정 값 변경
# 행 우선 접근 방법으로만 가능
df.loc['이슬이', '수학'] = 99
print('이슬이의 변경된 수학 점수는 %d 점' % df.loc['이슬이', '수학'])
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# DataFrame에서 Index(행) 이름만 추출
print(df.index) # 객체 형식
print(list(df.index)) # 리스트 변환
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# DataFrame에서 Column(열) 이름만 추출
print(df.columns) # 객체 형식
print(list(df.columns)) # 리스트 변환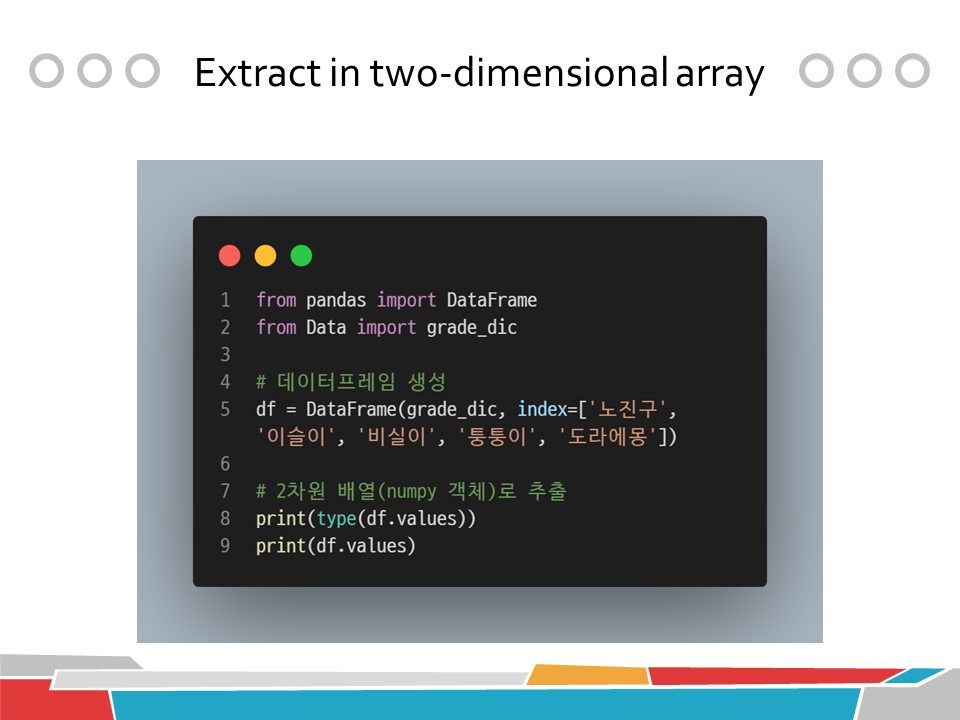
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 2차원 배열(numpy 객체)로 추출
print(type(df.values))
print(df.values)
from pandas import DataFrame
from Data import grade_dic
# 데이터프레임 생성
df = DataFrame(grade_dic, index=['노진구', '이슬이', '비실이', '퉁퉁이', '도라에몽'])
# 전치(열과 컬럼이 바뀐 형태) 구하기
df_t = df.T
print(df_t)반응형