
ETC/DailyRoutine
[방송통신대학교]대학수학의 이해 2학기 중간과제물
AnKiWoong
2022. 11. 4. 20:28
반응형
1.
저는 CAS와 유사한 Python Pandas를 가지고 스터디 그룹을 했었습니다.
Pandas 는 데이터 조작 및 분석 도구입니다.
wxmaxima와 Panas가 다른 점은 Maxima는 Lisp로 작성된 꽤 완전한 컴퓨터 대수 체계와 기호와 연산을 강조하지만 Python은 Pandas는 Perl, Ruby, Scheme 또는 Java에 필적하는 명확하고 강력한 객체 지향 프로그래밍 언어입니다.
예를 들어, 2020년도 2월 10일에 박스 오피스 순위를 분석해보면
# 영화 진흥원에서 발급받은 API키
# kobis.or.kr
kobis_api_key = ''
# 요청에 필요한 파라미터(API)
# key -> 문자열(필수) / 발급받은 키 값을 입력
# targetDt -> 문자열(필수) / 조회하고자 하는 날짜를 yyyymmdd 형식으로 입력
# 형식은 JSON
# 영화진흥원 API URL
kobis_api_url = 'http://www.kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.json?key=%s&targetDt=%s'
# 날짜 동적 생성(현재날짜 - 1일)
# 파라미터로 전달하기 위한 하루 전 날짜값 만들기
today = dt.datetime.now() # 오늘날짜
delta = dt.timedelta(days=-1) # 하루 전을 의미하는 timedelta객체
yesterday = today + delta # 오늘 날짜와 timedelta 연산
yesterday_str = yesterday.strftime('%Y%m%d') # yyyymmdd 형식 문자열로 변환
# API키와 날짜를 조합하여 접속할 URL 구성
# http://www.kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.json?key=발급받은키&targetDt=하루전날짜
api_url = kobis_api_url % (kobis_api_key, yesterday_str)
print(api_url)
# URL에 접속해서 결과를 가져옴
r = requests.get(api_url)
# 접속에 실패한 경우(status_code가 200이 아닌경우는 모두 에러 간주)
if r.status_code != 200:
# 에러코드와 에러메시지 출력
print('[%d Error] %s' % (r.status_code, r.reason))
# 프로그램 강제 종료
quit()
# 가져온 결과를 딕셔너리로 변환
r.encoding = 'utf-8'
result = json.loads(r.text)
print(result)
# 결과에서 영화 목록 배열을 데이터프레임으로 변환
df = DataFrame(result['boxOfficeResult']['dailyBoxOfficeList'])
print_df(df.head())
# 분석에 필요한 컬럼 추출하기
# 영화제목과 관람객수만 필터링 -> 막대그래프 생성
df = df.filter(items=['movieNm', 'audiCnt'])
print_df(df.head())
# 영화제목 -> 데이터프레임 인덱스
# 영화이름을 딕셔너리의 리스트로 사용하기
movie_list = list(df['movieNm']) # -> 영화이름만 리스트로 추출
index_dict = {} # -> 인덱스 이름 변경사항을 설정할 딕셔너리
for i, v in enumerate(movie_list): # -> {현재인덱스: 신규인덱스} 형식으로 재구성
index_dict[i] = v
# 딕셔너리의 인덱스와 컬럼이름을 변경
df.rename(index=index_dict, columns={'audiCnt': '관람객수'}, inplace=True)
# 영화제목에 대한 열은 삭제
df.drop('movieNm', axis=1, inplace=True)
# 변환결과 확인
print_df(df.head())
# 통계를 수행할 컬럼의 데이터 확인
# 관람객수 열 확인
print_df(df['관람객수'])
# pandas.to_numeric : 숫자 형식으로 형변환
# 관람객수 열의 타입을 숫자 형식으로 변환
df['관람객수'] = df['관람객수'].apply(pd.to_numeric)
# dtype : int64 -> int 형식으로 형 변환 확인
# 관람객수 열 재확인
print_df(df['관람객수'])
# 특정 열로 내림차순 정렬
# ascending=False 내림차순
# ascending=True 오름차순 (기본값)
df.sort_values('관람객수', inplace=True, ascending=True)
print_df(df)
# 관람객 수가 집계 되어 있지 않은 경우도 있기때문에 결측치 제거
# 결측치가 있는 모든 행 삭제
df = df.dropna()
empty_sum = df.isnull().sum()
print_df(empty_sum)
# 그래프 만들기
plt.rcParams['font.family'] = 'NanumGothic' # 한글 폰트 지정(나눔고딕)
plt.rcParams['font.size'] = 14 # 그래프 폰트 사이즈(14)
plt.rcParams['figure.figsize'] = (16, 8) # 그래프 사이즈(16 x 8)
# 전체 컬럼에 대한 시각화
df.plot.barh() # 막대그래프
plt.grid() # 격자무늬
plt.title('%s 박스오피스 순위' % yesterday_str) # 그래프 제목
plt.legend() # 범주
plt.savefig('boxoffice_daily.png', dpi=200) # 그래프 저장(dpi -> 해상도)
plt.show() # 그래프 보기
plt.close() # 그래프 종료


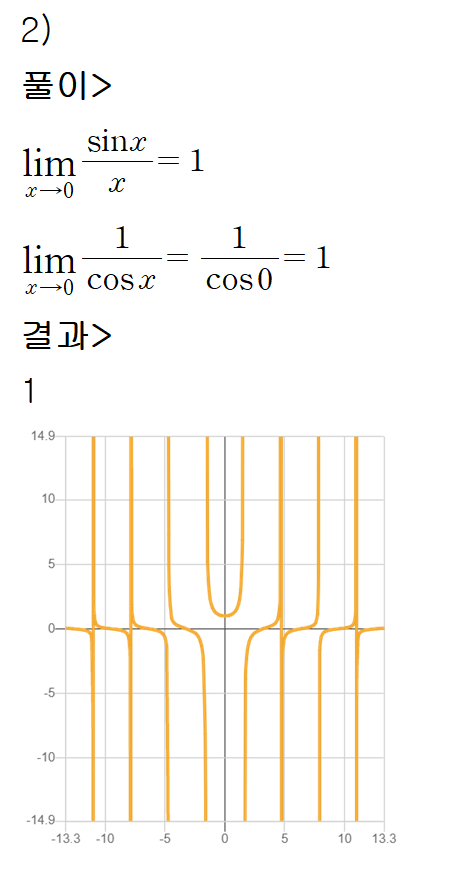
반응형