Q>
http://books.toscrape.com/catalogue/category/books/mystery_3/index.html
Mystery | Books to Scrape - Sandbox
£59.48 In stock
books.toscrape.com
해당 사이트에서 Title 와 Price를 가져와서 CSV File 저장하기
A>
1. 크롤링할 부분 파악
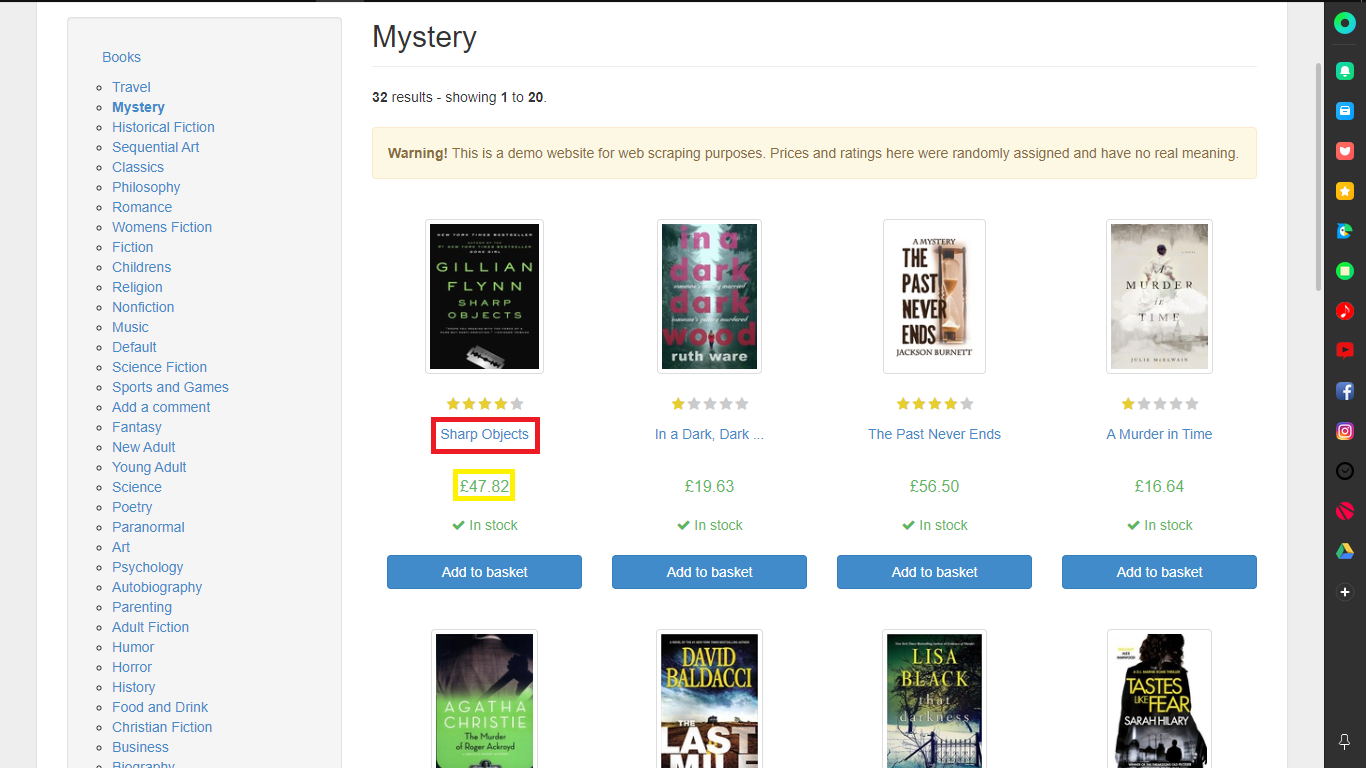
빨간색 부분 Title / 노란색 부분 Price
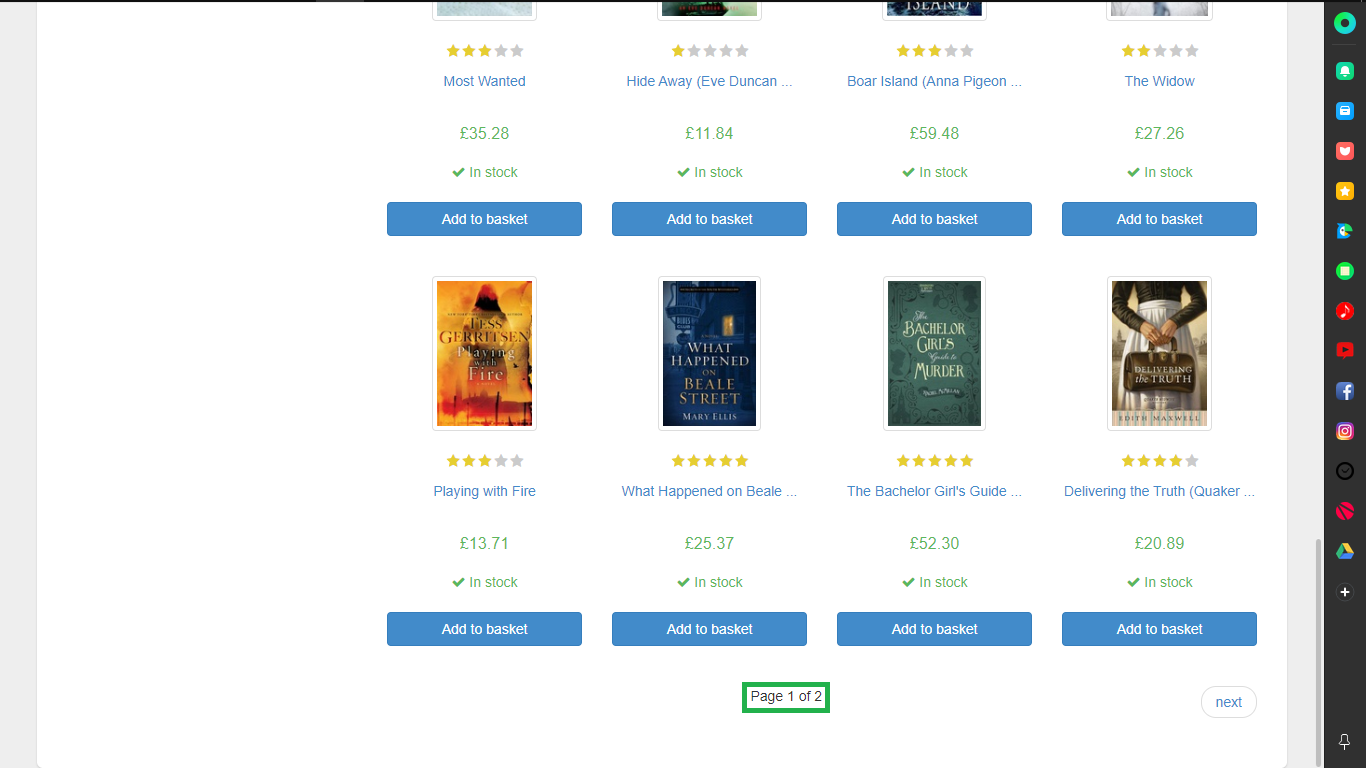
초록색 부분 페이지 수
2. 가져올 부분 개발자 도구에서 파악
- Title
- Price
- Page
3. 크롤링 함수 모듈 작성
import requests
from bs4 import BeautifulSoup
# 특정 셀렉터에 대하여 파싱한 결과를 List로 반환
def select(self, url, selector='html', encoding='utf-8'):
# 웹 페이지 접속 함수를 호출하여 소스코드 리턴받기
source = self.get(url, encoding)
# 리턴값이 없다면 처리 중단
if not source:
return None
# 웹 페이지의 소스코드 HTML 분석 객체로 생성
soup = BeautifulSoup(source, 'html.parser')
# CSS 선택자를 활용하여 가져오기를 원하는 부분 지정
# -> list로 리턴
return soup.select(selector)
4. 페이지 부분 크롤링 부분
- Page 1 of 2는 1 ~ 2 range로 범위 잡을 수 있는 것을 파악 후 작성
page_list = []
page_n = crawler.select(url, selector='.pager > li.current')
for h in page_n:
page_list.append(h.text.strip().split())
title_list = []
price_list = []
for n in range(int(page_list[0][1]), int(page_list[0][-1]) + 1):
url_s = 'http://books.toscrape.com/catalogue/category/books/mystery_3/page-{}.html'.format(n)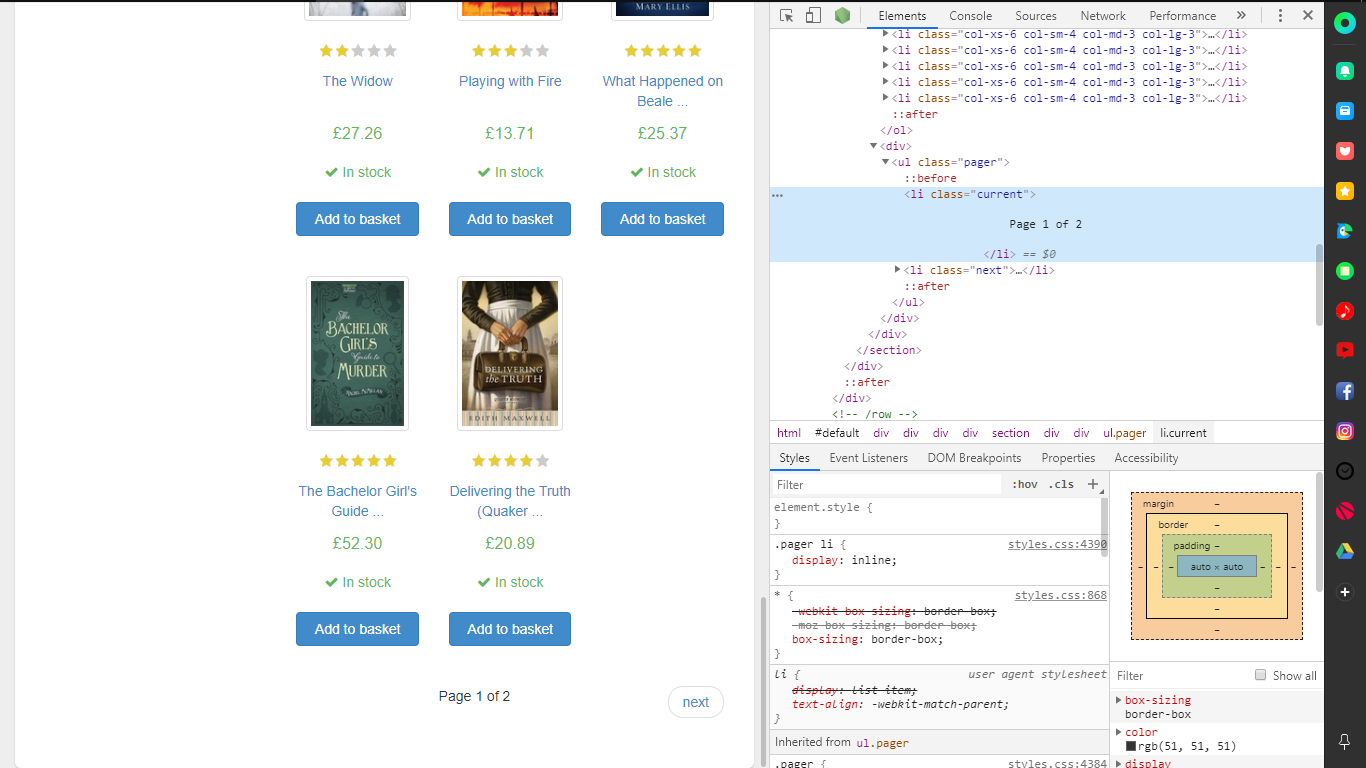
- 페이지 규칙 찾기
페이지 부분에서 다음 버튼을 누르면 주소가 바뀌는데 규칙을 찾을수 있는데
mystery_3 -> 카데고리
page-x.html -> 페이지 html
을 확인할 수 있다.
- 페이지 만들기
출력물을 보면 [['Page', '1', 'of', '2']] 라고 나오는것을 확인할 수 있다.
여기서 필요한것은 1 / 2 두개만 필요하다.
그러므로 for 문을 활용하여 범위 잡을 수 있다.
결국 시작 페이지와 끝 페이지를 잡을 수 있다.
- Title 추출하기
title_list = []
dom1 = crawler.select(url_s, selector='.product_pod > h3 > a')
for i in dom1:
title_list.append(i.text)
Title에 개발자도구로 보면 위치를 찾을수 있다.
이를 출력하면 시작 페이지 부터 끝 페이지까지 Title 만 가져오는것을 볼 수 있다.
['Sharp Objects', 'In a Dark, Dark ...', 'The Past Never Ends', 'A Murder in Time', 'The Murder of Roger ...', 'The Last Mile (Amos ...', 'That Darkness (Gardiner and ...', 'Tastes Like Fear (DI ...', 'A Time of Torment ...', 'A Study in Scarlet ...', 'Poisonous (Max Revere Novels ...', 'Murder at the 42nd ...', 'Most Wanted', 'Hide Away (Eve Duncan ...', 'Boar Island (Anna Pigeon ...', 'The Widow', 'Playing with Fire', 'What Happened on Beale ...', "The Bachelor Girl's Guide ...", 'Delivering the Truth (Quaker ...', 'The Mysterious Affair at ...', 'In the Woods (Dublin ...', 'The Silkworm (Cormoran Strike ...', 'The Exiled', "The Cuckoo's Calling (Cormoran ...", 'Extreme Prey (Lucas Davenport ...', 'Career of Evil (Cormoran ...', "The No. 1 Ladies' ...", 'The Girl You Lost', 'The Girl In The ...', 'Blood Defense (Samantha Brinkman ...', "1st to Die (Women's ..."]
- Price 추출하기
price_list = []
dom2 = crawler.select(url_s, selector='.product_price > p.price_color')
for j in dom2:
price_list.append(j.text.lstrip('£'))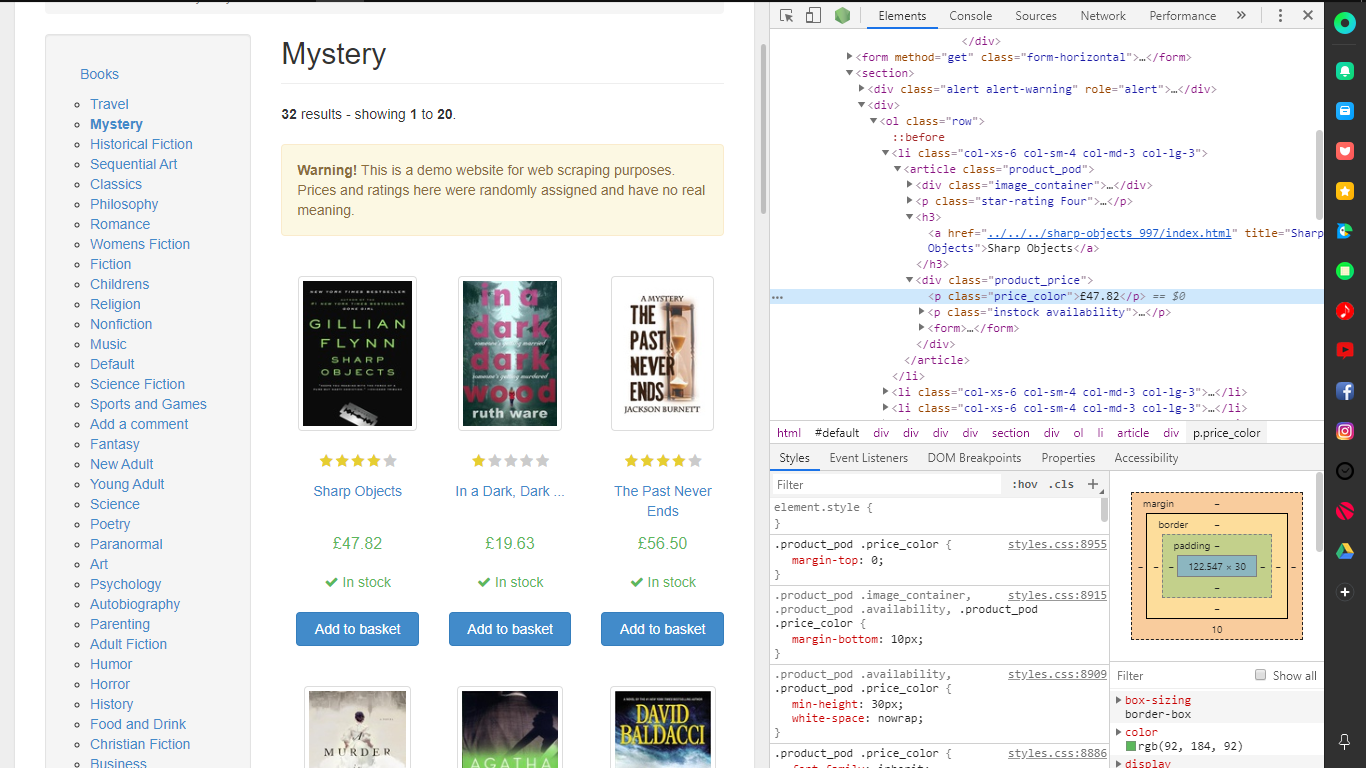
Price에 개발자도구로 보면 위치를 찾을 수 있다.
이를 출력하면 시작 페이지 부터 끝 페이지까지 Price만 가져오는것을 볼 수 있다.
그러나 이를 CSV로 파일을 작성하면 앞에 파운드 부분이 에러 처리가 되는 것을 볼 수 있다.
그러므로 파운드를 제거 하고 CSV파일을 작성하게 앞에 부분을 삭제하게 한다.
['47.82', '19.63', '56.50', '16.64', '44.10', '54.21', '13.92', '10.69', '48.35', '16.73', '26.80', '54.36', '35.28', '11.84',
'59.48', '27.26', '13.71', '25.37', '52.30', '20.89', '24.80', '38.38', '23.05', '43.45', '19.21', '25.40', '24.72', '57.70', '12.29', '15.85', '20.30', '53.98']
5. 데이터 딕셔너리화
di = {
'title': title_list,
'price': price_list
}Pandas에서 저장할 데이터를 딕셔너리 형태로 작성한다.
{'title': ['Sharp Objects', 'In a Dark, Dark ...', 'The Past Never Ends', 'A Murder in Time', 'The Murder of Roger ...', 'The Last Mile (Amos ...', 'That Darkness (Gardiner and ...', 'Tastes Like Fear (DI ...', 'A Time of Torment ...', 'A Study in Scarlet ...', 'Poisonous (Max Revere Novels ...', 'Murder at the 42nd ...', 'Most Wanted', 'Hide Away (Eve Duncan ...', 'Boar Island
(Anna Pigeon ...', 'The Widow', 'Playing with Fire', 'What Happened on Beale ...', "The Bachelor Girl's Guide ...", 'Delivering the Truth (Quaker ...', 'The Mysterious Affair at ...', 'In the Woods (Dublin ...', 'The Silkworm (Cormoran Strike ...', 'The
Exiled', "The Cuckoo's Calling (Cormoran ...", 'Extreme Prey (Lucas Davenport ...', 'Career of Evil (Cormoran ...', "The No. 1
Ladies' ...", 'The Girl You Lost', 'The Girl In The ...', 'Blood Defense (Samantha Brinkman ...', "1st to Die (Women's ..."], 'price': ['47.82', '19.63', '56.50', '16.64', '44.10', '54.21', '13.92', '10.69', '48.35', '16.73', '26.80', '54.36', '35.28', '11.84', '59.48', '27.26', '13.71', '25.37', '52.30', '20.89', '24.80', '38.38', '23.05', '43.45', '19.21', '25.40', '24.72', '57.70', '12.29', '15.85', '20.30', '53.98']}
6. 데이터 프레임화
df = DataFrame(di, columns=['title', 'price'])
7. CSV 파일 작성
df.to_csv('title_price.csv', encoding='utf-8')
8. Code
from Crawler import crawler
from pandas import DataFrame
url = 'http://books.toscrape.com/catalogue/category/books/mystery_3/index.html'
page_list = []
page_n = crawler.select(url, selector='.pager > li.current')
for h in page_n:
page_list.append(h.text.strip().split())
title_list = []
price_list = []
for n in range(int(page_list[0][1]), int(page_list[0][-1]) + 1):
url_s = 'http://books.toscrape.com/catalogue/category/books/mystery_3/page-{}.html'.format(
n)
dom1 = crawler.select(url_s, selector='.product_pod > h3 > a')
dom2 = crawler.select(url_s, selector='.product_price > p.price_color')
for i in dom1:
title_list.append(i.text)
for j in dom2:
price_list.append(j.text.lstrip('£'))
di = {
'title': title_list,
'price': price_list
}
df = DataFrame(di, columns=['title', 'price'])
df.to_csv('title_price.csv', encoding='utf-8')
9. CSV 파일
'Python_Crawling > Crawling' 카테고리의 다른 글
| [Crawling]Python Study - PPT Presentation Material - 2 (0) | 2019.12.16 |
|---|---|
| [Crawling]Python Study - PPT Presentation Material - 1 (0) | 2019.12.16 |
| [Study Group]명언 + 위인 가져오기(selenium) (0) | 2019.10.26 |
| Naver News WordCloud 2 (0) | 2019.06.04 |
| Naver News WordCloud 1 (0) | 2019.06.04 |



